
Что будет когда генератор sql
MS SQL: генерация псевдослучайных данных с использованием newID(). Возможности и подводные камни
Известно, что встроенная функция newID() широко используется разработчиками не только по прямому назначению — то есть для генерации уникальных первичных ключей, но и в качестве средства для генерации массивов псевдослучайных данных.
В составе встроенных функций, newID() фактически единственная, которая не только non-deterministic, но можно сказать и «super-non-deterministic», т.к. в отличие от всех остальных, она способна выдавать новое значение для каждой новой строки, а не одно и то же для всего батча — что делает ее чрезвычайно полезной для подобной массовой генерации. Кроме newID() этим свойством обладает еще newSequentialID(), однако ее использование где-либо, кроме как в задании дефолтного значения колонок типа uniqueidentifier, запрещено.
За примерами далеко ходить не надо — ниже код:
или вот этот (если кажется, что checksum — трудоемкая операция):
Сгенерирует нам таблицу из 100 случайных целых чисел в диапазоне от 0 до 999.
Для плавающих чисел можно использовать свойство функции rand() инициализировать генератор целым числом:
В данном случае rand() используется по сути просто как преобразователь диапазона int32 в диапазон [0..1). Статистическая проверка качества распределения этим методом на количестве записей порядка миллиона показывает, что оно не уступает стандартному использованию rand(), инициализированному один раз, и далее используемому в цикле. Поэтому — можете смело использовать.
Еще один интересный вариант — генерация нормально-распределенных данных. Здесь будем использовать метод Бокса-Мюллера:
Желающие могут проверить, что сгенерированное распределение очень близко к нормальному, построив график.
Все это хорошо работает и позволяет очень быстро сгенерировать хоть десяток миллионов записей, не используя решения «в лоб» типа циклов, курсоров, или даже вставки записей по одной в базу из слоя приложения. Нужно только убедиться, что таблицы, которые вы используете как источник строк, имеют достаточную емкость, и либо увеличить количество CROSS JOIN’ов, либо использовать табличные переменные с нужным количеством строк в качестве источника.
Однако, тема не только об этом. В подавляющем большинстве случаев сгенерированные строки материализуются, то есть вставляются в постоянную или временную таблицу, либо в табличную переменную. Если это так, то дальше можно не читать — материализованные данные будут работать отлично. Однако, встречаются случаи, когда вышеуказанные стейтменты используются в подзапросах. И вот здесь появляются труднообъяснимые на первый взгляд особенности поведения SQL engine. Рассмотрим их на примерах, а затем попытаемся проанализировать, почему так происходит, и как с этим бороться:
Для начала просто напишем statement с newID() в subquery и запустим его несколько раз в цикле:
Код работает ожидаемо — выдает 5 резалтсетов, в каждом строго одна запись с числом в диапазоне от 0 до 4. Скриншота результатов я не привожу — когда и так все в порядке, смысла в них мало.
Теперь интереснее. Пробуем поджойнить результат из SUBQ на какую-нибудь другую таблицу. Ее можно создать, а можно поджойнить subquery на subquery — результат от этого не изменится. Пишем:
Смоторим на скриншот результата выполнения — и медленно сползаем под стул — количество строк в каждом резалтсете не равно строго 1. Где-то пусто (это еще можно хоть как-то объяснить — не сработал INNER JOIN из-за выхода RNDIDX из диапазона [0..4] (что само по себе невероятно!)), а где-то — больше одной (!) записи.

Теперь делаем невинное изменение — меняем INNER на LEFT:
Выполняем — все стало работать правильно (!) — проверерьте плз сами, скриншота для правильной работы я не делал. Заметьте, что поскольку для любого значения RNDIDX из диапазона [0..4], которое способно выдать сабквери SUBQ, всегда есть значение VAL из сабквери NUM, то с точки зрения логики результат LEFT и INNER JOIN должен быть одинаков. Однако по факту это не так!
Еще один тест — возвращаем INNER, но добавляем TOP / ORDER BY в первый сабквери. Зачем — об этом позже, давайте просто попробуем:
Все опять работает правильно! Мистика!
Погуглив, выясняем, что с подобным поведением периодически сталкиваются SQL-разработчики со всего мира — примеры здесь, или здесь
Люди предполагают, что материализация subquery помогает. Действительно, если переписать пример, выбрав сначала записи в явном виде во временную таблицу, а затем только поджойнив, все работает нормально. Почему же на нормальную работу влияет замена INNER на LEFT, или добавление TOP / ORDER BY там, где это не нужно? Все потому же — в одном случае присутствует материализация результатов subquery, в другом — нет. Нагляднее разницу может показать анализ плана более развернутого случая, например вот этого:

Мы видим, что запрос сращивает два потока строк до вычисления значения колонки, зависящей от newID(). Это может происходить потому, что SQL engine считает, что значение, возвращаемое newID(), хоть и non-deterministic, но не изменяется в течение всего батча. Однако, это не так — и скорее всего поэтому запрос работает неправильно. Теперь меняем INNER на LEFT, и смотрим план:

Ага, LEFT JOIN заставил SQL engine выполнить Compute Scalar перед объединением потоков, поэтому наш запрос стал работать правильно.
И наконец, проверим версию с добавлением TOP / ORDER BY:

Собственно, диагноз ясен. MS SQL не учитывает особенности newID(), и соответственно, неправильно строит планы, полагаясь на константное значение, возвращаемое функцией в скоупе батча. На эту особенность есть воркэраунд — заставлять SQL engine любыми способами материализовать выборку, перед тем как ее использовать в зависимых запросах. Каким способом вы будете материализовать — дело ваше, однако лучше всего, наверное, использовать табличные переменные, особенно если размер подвыборки невелик. Иначе результат, мягко говоря, не 100% гарантирован; кроме того, нет никакой гарантии, что однажды вы сами, или кто-нибудь другой не отревьюит код, выкинув «ненужные» TOP / ORDER BY или мудро заменив LEFT на INNER.
Собственно, все. Удачного SQL-программирования!
Как получить последовательность дат в указанном промежутке на T-SQL
Всем привет! Сегодня мы поговорим о том, как на языке T-SQL можно сформировать последовательность дат в указанном диапазоне, т.е. когда требуется получить все даты между двумя определенными датами, при этом чтобы каждое значение даты в результирующем наборе данных было в отдельной строке.

Допустим, Вам требуется вывести все даты, начиная с 01.01.2020 по 12.01.2020, иными словами, Вам необходимо сформировать следующую таблицу.
| dt |
| 01.01.2020 |
| 02.01.2020 |
| 03.01.2020 |
| 04.01.2020 |
| 05.01.2020 |
| 06.01.2020 |
| 07.01.2020 |
| 08.01.2020 |
| 09.01.2020 |
| 10.01.2020 |
| 11.01.2020 |
| 12.01.2020 |
И первое, что может прийти в голову, это использовать или оператор UNION, или конструктор табличных значений VALUES, и в этом конкретном случае, когда требуется сформировать всего 12 записей, это может показаться достаточно простой задачей, однако представим, что нам требуется сформировать даты за большой промежуток времени, например за год, или за несколько лет, тогда этот способ сразу отпадает, так как вручную формировать тысячи строк, наверное, как минимум очень трудоемко, т.е. не очень эффективно. А если еще представить, что нам требуется формировать такие списки дат постоянно и динамически, т.е. начало и конец периода постоянно будут меняться, то такой ручной способ точно не подходит.
Поэтому сейчас мы рассмотрим способы для автоматической генерации последовательности дат.
- Способы реализации генерации последовательности дат
- Способ 1 – использование цикла WHILE
- Способ 2 – использование рекурсивного обобщенного табличного выражения
- Пример использования функций для генерации последовательности дат
Способы реализации генерации последовательности дат
В интернете можно встретить решения, которые подразумевают использование вспомогательных таблиц, однако в языке T-SQL все это можно сделать без каких-то внешних вспомогательных инструментов, т.е. с использованием только стандартных конструкций языка.
При этом есть несколько способов, как можно генерировать последовательность дат, в частности мы рассмотрим 2, и для каждого решения создадим табличную функцию, чтобы можно было просто обращаться к функции, передав в нее две даты, т.е. начало периода и его окончание, а в ответ получать таблицу, состоящую из всех дат в заданном промежутке.
Сразу скажу, что оба способа по производительности примерно одинаковые и позволяют практически мгновенно сформировать последовательность дат за десятилетия и даже столетия.
Способ 1 – использование цикла WHILE
Первый способ подразумевает использование обычного цикла WHILE.
В отличие от ситуаций, когда нам требуется сформировать последовательность чисел или просто набор тестовых данных, эту тему мы рассматривали в отдельном материале – Как сформировать на языке T-SQL большое количество строк, в данном случае использовать цикл можно, так как даже если нам потребуется сформировать последовательности дат за несколько веков, у нас получится всего несколько десятков тысяч записей, которые сгенерируются достаточно быстро, тем более такое скорей всего будет требоваться только в каких-то частных случаях.
Итак, вот инструкция T-SQL, которая создает табличную функцию для генерации последовательности дат.
Принимает она два параметра: первый — начальная дата, и второй — дата окончания. В ответ она возвращает таблицу со всеми датами в этом промежутке.
Способ 2 – использование рекурсивного обобщенного табличного выражения
Второй, альтернативный способ генерации последовательности дат, подразумевает использование рекурсивного обобщенного табличного выражения.
Данная табличная функция работает точно так же как и предыдущая, и принимает ровно те же самые параметры.
Пример использования функций для генерации последовательности дат
Теперь, когда у нас есть функция для генерации последовательности дат, давайте представим, что нам необходимо сформировать последовательность дат за 2020 год, т.е. нам нужны даты в промежутке начиная с 01.01.2020 и заканчивая 31.12.2020.
В итоге у нас должно быть 366 записей, т.е. отдельная запись для каждого дня года (в 2020 году 366 дней, так как это високосный год).
Таким образом, чтобы получить данную последовательность дат, мы обращаемся к нашей табличной функции и передаём в нее соответствующие значения (начало и конец года).
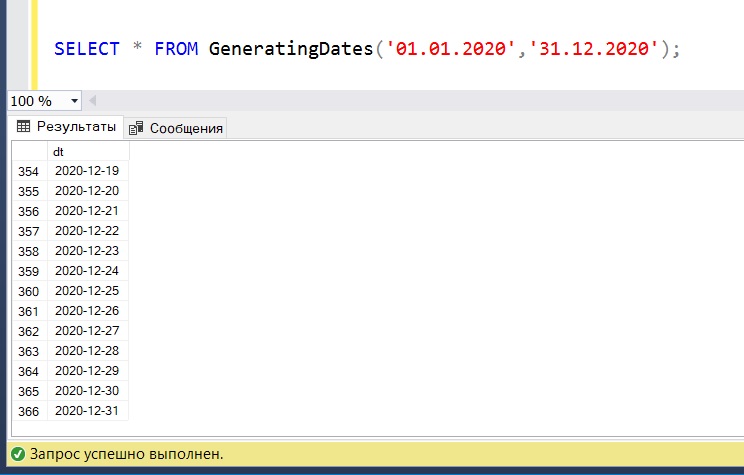
В результате мы получили то, что нам и было нужно.
Таким образом, мы можем генерировать последовательность дат за любой промежуток времени.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Что будет когда генератор sql
Имя генератора должно являться обычным идентификатором метаданных базы данных: максимум 31 символ, без специальных символов за исключением символа подчеркивания « _ » (если вы не используете регистрозависимые идентификаторы в кавычках). Команды и операторы SQL, применяемые к генераторам, перечислены ниже. Их использование более подробно будет описано в разделе Использование операторов для генераторов.
Операторы DDL (Data Definition Language — язык определения данных):
Операторы DML (Data Manipulation Language — язык манипуляции данными) в клиентском SQL:
Операторы DML в PSQL (Procedural SQL — процедурный SQL — расширение языка, используемое в хранимых процедурах и триггерах):
Синтаксис, рекомендованный для Firebird 2
Хотя в СУБД Firebird 2 все еще полностью поддерживается традиционный синтаксис, существует рекомендуемый DDL-эквивалент для СУБД Firebird 2:
А для операторов DML:
В настоящее время рекомендуемый синтаксис не поддерживает шаг изменения (инкремент), отличный от 1. Это ограничение будет снято в будущих версиях. Пока используйте GEN_ID , если вы хотите использовать другое значение для шага изменения значения.
Использование операторов для генераторов
Доступность операторов и функций зависит от того, где вы их используете:
Клиентский SQL – используемый вами язык, когда вы, в качестве клиента, общаетесь с сервером СУБД Firebird.
PSQL – язык программирования на стороне сервера, используемый в хранимых процедурах и триггерах СУБД Firebird.
Создание генератора (« Insert »)
Предпочтительно для СУБД Firebird 2 и старше:
Невозможно. Так как вы не можете изменять метаданные базы данных в хранимых процедурах (stored procedures) или триггерах, вы не можете создавать генераторы.
Замечание
В СУБД Firebird 1.5 и старше вы можете обходить это ограничение с помощью оператора EXECUTE STATEMENT .
Получение текущего значения (« Select »)
Этот синтаксис является единственной возможностью получить текущее значение генератора в СУБД Firebird 2.
Замечание
В утилите для СУБД Firebird isql есть две дополнительные команды для получения текущего значения генератора:
Первая показывает текущее значение конкретного генератора. Вторая команда делает то же самое для всех не системных генераторов базы данных.
Предпочтительный для СУБД Firebird 2 эквивалент, как вы можете предположить:
Пожалуйста, обратите внимание, что команды SHOW. доступны только в инструменте isql . В отличие от GEN_ID , вы не можете использовать их из других клиентов (если эти клиенты не используют isql в качестве клиента).
СУБД Firebird 2: тот же самый синтаксис.
Генерация следующего значения (« Update » + « Select »)
Так же, как и в случае получения текущего значения, это выполняется с помощью GEN_ID , но в этом случае вы используете значение шага, равное 1. При этом СУБД Firebird:
получает текущее значение генератора;
увеличивает его на 1;
возвращает измененное значение.
Новый синтаксис, который предпочтителен для СУБД Firebird 2, полностью отличается:
Предпочтительно для СУБД Firebird 2 и старше:
Прямое указание определенного значения генератора (« Update »)
Это удобно для установки в генераторе значения, отличного от 0 (которое является значением по умолчанию после его создания), например, в скрипте для создания базы данных. Аналогично CREATE GENERATOR , это оператор DDL (не DML).
Предпочтительный синтаксис для СУБД Firebird 2 и старше:
Внимание
Это больше похоже на « грязный трюк » в попытке сделать то, что в обычных условиях сделать нельзя и не д о лжно в хранимых процедурах и триггерах: установка значений генераторов. В них можно получать , а не устанавливать значения.
Удаление генератора (« Delete »)
Предпочтительно для СУБД Firebird 2 и старше:
Невозможно, поскольку. (То же самое объяснение, что и для создания: вы не можете [или, скорее, не должны] изменять метаданные в PSQL.)
Удаление генератора не освобождает место, которое он занимает, для использования нового генератора. На практике это редко приводит к проблемам, поскольку большинство баз данных не имеют десятков тысяч генераторов, которые позволяет создавать СУБД Firebird. Но если ваша база данных рискует превысить 32767 генераторов, вы можете освободить место неиспользуемых генераторов путем выполнения операции резервного копирования/восстановления базы данных (backup/restore). При этом аккуратно упаковывается таблица RDB$GENERATORS , переназначаются идентификаторы (ID), образуя непрерывную последовательность. В зависимости от ситуации, восстановленной базе данных может понадобиться меньше страниц для хранения значений генераторов.
Удаление генераторов в старых версиях IB и Firebird
СУБД InterBase 6 и более ранние версии, точно так же, как и ранние версии СУБД Firebird, предшествующие версии 1.0, не имеют команды DROP GENERATOR . Единственным способом удалить генератор является оператор:
. с последующим циклом резервирования/восстановления базы данных (backup/restore).
Для этих версий СУБД с максимальным количеством генераторов около пары сотен гораздо более вероятно появление необходимости использованть место от удаленных генераторов.
Генераторы и триггеры. Реализация автоинкрементного поля
Генераторы
Генераторами называется специальная область данных, которая хранится в базе данных и содержит какое то целое число. Генераторы — это счетчики, но в отличие от локальных БД, увеличение значения этих счетчиков осуществляется с помощью триггеров.
В основном, генераторы используют для создания автоинкрементных полей. Для каждого такого поля придется создавать собственный генератор . Генератор , совместно со специальным триггером, гарантирует, что значение этого поля всегда будет уникальным. Создаются генераторы с помощью оператора CREATE GENERATOR :
Внимание! Генераторы можно создавать, но удалить их не получится, поэтому в реальной базе данных прежде продумайте, какие генераторы у вас будут, а потом только создавайте их. Откройте утилиту IBConsole , войдите в локальный сервер и откройте нашу базу данных FIRST . Затем запустите Interactive SQL , и создайте генератор Gen1, как в примере выше. Затем выделите раздел «Generators» в дереве серверов, и в правой части вы увидите наш генератор , а также его текущее значение :
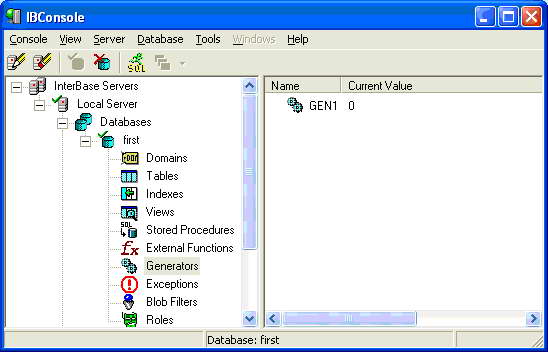
Как видно из рисунка, генератору сразу присваивается значение 0. Тем не менее, во избежание возможных ошибок, вторым шагом нередко присваивают генератору это значение оператором SET GENERATOR :
Выполните этот пример с помощью утилиты Interactive SQL . Таким образом, генераторам можно присваивать любое целое значение , даже отрицательное.
Иногда бывает необходимым присваивать генератору не нулевое, а другое значение . Например, если вы перенесли базу данных из Paradox в InterBase . В этом случае, таблица уже содержит записи, которые пронумерованы. Автоинкрементное поле при переносе превращается в INTEGER . Требуется посмотреть последнее значение этого поля, и присвоить генератору именно его.
Увеличение шага генератора
Как вы понимаете, для ввода каждой следующей записи вовсе нет необходимости открывать IBConsole , смотреть значение генератора и вручную устанавливать новое значение . Для этого используется специальная процедура GEN_ID() (выполнять этот пример не нужно):
Процедура содержит два параметра. Первый — имя генератора , второй — шаг, на который требуется увеличить значение . Обычно эту процедуру используют в триггерах, но можно выполнить ее и вручную, с помощью Interactive SQL . Выполните следующий запрос :
В нижнем окне Interactive SQL будет выведен результат:

Как видно из рисунка, мы получили значение 1. Выполните также команду COMMIT, чтобы завершить транзакцию, затем закройте Interactive SQL . Выделите раздел Generators и убедитесь, что значение изменилось. Что, собственно, произошло? Дело в том, что когда вы создаете новую базу данных, InterBase прежде всего создает в ней собственные системные таблицы. Одной из таких таблиц является RDB$DATABASE , которая всегда хранит только одну запись с некоторыми системными параметрами базы данных . Эту же таблицу иногда применяют для «пустых» запросов, которые возвращают значение одной из переменных или вычисляемое значение . Нашим предыдущим запросом мы вначале увеличили значение генератора на 1, затем вывели его на экран оператором SELECT. Узнать текущее значение генератора , не увеличивая его, можно строкой:
где в процедуре GEN_ID() указывается шаг 0.
Поскольку генератор может хранить отрицательные значения, а шаг процедуры GEN_ID также может быть отрицательным, то можно установить и обратный автоинкремент, где значения не увеличиваются, а уменьшаются. Впрочем, такой возможностью обычно не пользуются.
Совет: если генератор уже находится в использовании, в рабочей базе данных, НИКОГДА не переустанавливайте его значений вручную — это чревато порчей целостности и достоверности данных.
Триггеры
Триггерами называются подпрограммы, которые всегда выполняются автоматически на стороне сервера, в ответ на изменение данных в таблицах БД.
Триггеры используют тот же встроенный язык программирования , что и хранимые процедуры, но отличаются от них прежде всего тем, что триггеры никогда не вызываются напрямую, ни из клиентских программ, ни с помощью IBConsole , ни из хранимых процедур или других триггеров . Зато в теле триггера можно обратиться к хранимой процедуре. Триггеры начинают действовать в ответ на какое то событие, например, удалили запись в таблице или изменили значение в каком то поле . Кроме того, в триггерах добавлена возможность обращаться к старым и новым значениям столбцов с помощью встроенных переменных OLD и NEW .
Триггер может выполняться в двух фазах изменения данных: до(Before) какого то события, или после(After) него. Синтаксис определения триггера следующий:
Как мы видим, создание триггера несколько отличается от создания хранимой процедуры , несмотря на то, что они используют один и тот же алгоритмический язык . Например, у триггера отсутствуют входные и выходные параметры . Разберем его синтаксис по частям.
[ACTIVE | INACTIVE]
Необязательный параметр определяет, будет триггер запускаться в ответ на событие, или не будет. По умолчанию устанавливается ACTIVE, то есть триггер будет запускаться. Отключение триггера иногда может быть полезным при отладке приложения.
Генерация первичных ключей для идентификации объектов словаря
SQLite
Движок этой БД автоматически генерирует уникальные значения при вставке новой записи в таблицу для столбца, имеющего атрибут PRIMARY KEY в случае, если в операторе INSERT пропустить данный столбец.
Чтобы получить значение, сгенерированное для первичного ключа, надо после выполнения оператора INSERT вызвать функцию API sqlite3_last_insert_rowid. Она вернет 64-битное значение — сгенерированный ключ.
Особенность данного механизма генерации — он начинает значения первичного ключа с 1. Таким образом, если нам по каким-то причинам важно получить для записи 0 в качестве первичного ключа, необходимо явно задать его в операторе INSERT, подавив автогенерацию.
MySQL
Уникальные первичные ключи генерируются сервером при вставке записей оператором INSERT в таблицу, которая содержит столбец первичного ключа с атрибутом AUTO_INCREMENT.
Сгенерированное значение первичного ключа можно получить двумя способами.
Во-первых, можно выполнить запрос SELECT LAST_INSERT_ID(). Необычный синтаксис оператора SELECT в данном случае является особенностью этой СУБД. Такой способ применяется в случае, когда нет возможности вызвать функции клиента MySQL, например при работе через ODBC, и в классе MySQL_DataAccessLayer, который обеспечивает доступ к словарю в рамках ORM библиотеки.
Более быстрый способ применим в случае работы с native API. Функция mysql_insert_id возвращает значение первичного ключа, созданное в последнем выполненном операторе INSERT. Этот вызов используют классы, используемые C++ кодом словаря.
Автоматическая генерация первичного ключа в этой СУБД имеет особенность, связанную с интерпретацией значения 0 по умолчанию. Дело в том, что без специальной настройки, вставка новой записи с явно указанным первичным ключом, равным 0, интерпретируется движком БД как вставка с NULL в поле ключа. Поэтому вставить в таблицу запись с 0 в поле первичного ключа невозможно — сервер сгенерирует для этой записи первичный ключ, например 1. И если мы выполняем скрипт загрузки SQL словаря, в котором значения первичного ключа уже заданы явно, то вполне возможно получить ошибку из-за нарушения уникальности первичного ключа на вставе следующей записи с первичным ключем=1. В документации по MySQL задание 0 для первичного ключа названо плохой практикой. Но если нулевое значение первичного ключа все-таки необходимо, то следует перед загрузкой таблиц выполнить команду
SET SESSION sql_mode=’NO_AUTO_VALUE_ON_ZERO’
Она запретит на время загрузки SQL в БД считать 0 равным NULL при вставке значений первичного ключа. Именно такие команды можно увидеть в скрипте загрузки грамматического словаря.
MS SQL
Данная СУБД также имеет возможность автоматической генерации первичных ключей. Для этого необходимо указать в операторе CREATE TABLE для соответствующего столбца атрибут IDENTITY.
Чтобы получить значение первичного ключа, сгенерированное в последнем выполненном операторе INSERT, необходимо выполнить запрос SELECT @@identity. Это напоминает соответствующий функционал в MySQL. Класс MSSQL_DataAccessLayer в ORM библиотеке использует именно такой способ.
Важная особенность механизма генерации первичных ключей, которую следует учитывать при загрузке словаря в БД — необходимо отключать генерацию в операторе BULK INSERT. Для этого перед BULK INSERT надо выполнить команду SET IDENTITY_INSERT . ON, а после вставки данных — команду SET IDENTITY_INSERT . OFF. Это позволит нормально вставлять значения в поле первичного ключа в ходе начальной загрузки словаря в базу данных.
Другая возможность генерации уникальных первичных ключей, имеющаяся в MS SQL, основана на типе данных uniqueidentifier и функции NEWID(). Тип uniqueidentifier хранит 16-байтовые значения GUID. Функция NEWID() возвращает новые уникальные значения, причем для нее декларируется глобальная уникальность значений, так как они основаны на использовании уникального (в теории) MAC адреса сетевой карты. В рамках грамматического словаря данный механизм не используется, так как работа с GUID’ами намного тяжелее, чем работа с 32-битными идентификаторами identity, как для сервера при операциях с индексами, так и в клиентском коде из-за большого размера данных.
FireBird
Данная СУБД не имеет механизма автоматической генерации первичных ключей, реализованных в SQLite, MySQL, MS SQL. Вместо этого необходимо использовать генераторы — специальные объекты в схеме, которые при каждом обращении к себе возвращают уникальное значение. Для каждой таблицы с помощью команды CREATE SEQUENCE создается свой генератор. Для получения очередного значение для первичного ключа выполняется запрос
select gen_id( имя_генератора,1) from rdb$database
В этом запросе фигурирует специальная служебная таблица с именем rdb$database, которая всегда имеет ровно 1 запись.
В функции gen_id можно задавать второй аргумент как 0 или -1, таким образом запрашивая текущее значение генератора или выполняя его декремент, но при работе с грамматическим словарем такие сценарии не используются.
В некоторых случаях может быть удобнее вместо явного обращения к генератору отдельным запросом перед командой INSERT создать триггер на вставку, который сработает перед добавлением кортежа в таблицу и в случае, если поле первичного ключа содержит NULL, обратиться к соответствующему генератору. Однако данный механизм не используется ни в скрипте создания словаря, ни при работе ORM.
Oracle
Для генерации уникальных первичных ключей в СУБД корпорации Oracle используется штатный механизм последовательностей (sequences), в целом аналогичный FireBird. Перед вставкой нового кортежа в таблицу мы генерируем значение первичного ключа с помощью запроса
SELECT имя_последовательности.NEXTVAL FROM DUAL
В данном запросе используется специальная таблица DUAL, которая всегда содержит единственную строку, так что результирующее множество будет содержать единственную запись. Класс Oracle_DataAccessLayer в ORM библиотеке словаря реализует именно такой подход к получению первичных ключей.
Генераторы
Генераторы являются идеальным средством для создания значений автоинкрементных уникальных ключей или серий значений числового столбца, а также других серий. Генераторы в базе данных объявляются оператором CREATE, как и любой другой объект базы данных:
CREATE GENERATOR AGenerator;
Генераторам может быть присвоено любое начальное значение:
SET GENERATOR AGenerator ТО 1;
ВНИМАНИЕ! Существуют строгие предупреждения по поводу переустановки значений генераторов, когда эти значения находятся в использовании — см. разд. «Предупреждения о переустановке значений генераторов» в этой главе.
Получение следующего значения
Для получения следующего значения вызывайте функцию SQL GEN_ID(ИмяГенератора, n), где имягенератора — имя генератора, а n — целое (диалект 1) или NUMERIC(18,0) (диалект 3), определяющее значение шага. Запрос:
SELECT GEN_ID(AGenerator, 2) from RDB$DATABASE;
возвращает число, которое на 2 больше последнего сгенерированного числа, и устанавливает значение генератора в сгенерированное значение.
Текущее значение генератора
SELECT GEN_ID(AGenerator, 0) from RDB$DATABASE;
возвращает текущее значение генератора без его увеличения[18].
PSQL, язык программирования Firebird, позволяет напрямую присваивать сгенерированное значение переменной:
DECLARE VARIABLE MyVar BIGINT;
MyVar = GEN_ID(AGenerator, 1);
Более подробную информацию об использовании генераторов в модулях PSQL — в особенности в триггерах — см. в главе 29[19].
Использование отрицательного шага
Аргумент шаг в GEN_ID может быть отрицательным. Следовательно, можно устанавливать или переустанавливать текущее значение генератора, передавая отрицательный аргумент или в виде целой константы, или в виде целого выражения. Эта возможность иногда используется как «трюк» для установки значений генератора в PSQL, поскольку в PSQL не могут использоваться такие команды DDL, как SET GENERATOR.
SELECT GEN_ID (AGenerator, -GEN_ID (AGenerator, 0)) from RDB$DATABASE;
устанавливает значение генератора в ноль.
Предупреждения о переустановке значений генераторов
Основное простое правило по переустановке значений генераторов в работающей базе данных — будь то в SQL, PSQL или в некотором интерфейсе администратора — не делать этого.
Основное достоинство значений генератора то, что они гарантированно являются уникальными. В отличие от других доступных пользователю операций Firebird генераторы работают вне контекста транзакций. Однажды сгенерированное, число установлено и не может быть изменено отменой транзакции. Это дает полную уверенность в том, что ничто не может вмешиваться в целостность последовательности чисел, предоставляемых генератором.
Оставьте переустановку значений генераторов в создаваемой базе данных для редких случаев, когда это требуется условиями проектирования. Например, некоторые бухгалтерские системы, написанные в старом стиле, передают журналы в таблицы истории с новым первичным ключом, очищают таблицу журналов и устанавливают последовательность первичных ключей в ноль в организациях с несколькими филиалами, выделяя диапазоны значений ключа каждого филиала в отдельный «фрагмент», чтобы гарантировать целостность ключей при репликации.
Никогда не переустанавливайте значения генератора в попытке скорректировать программные ошибки, ошибки ввода данных или для «устранения промежутков» в последовательности значений[20].
Читайте также
Онлайн-генераторы
Онлайн-генераторы www.csssprites.com. Обладает довольно минималистичным дизайном, есть возможность загружать несколько исходных файлов.www.printf.ru/spritr/. В этом инструменте есть возможность загружать несколько файлов, очень милый дизайн, но в целом настроек мало.spritegen.website-performance.org.
9.2. Генераторы паролей
9.2. Генераторы паролей Генераторы паролей используются для создания особо сложных и длинных паролей. Генераторов паролей – несчетное множество. Каждый школьник, обладая начальными навыками программирования, может создать программу, генерирующую случайную
Генераторы — лучшие друзья первичных ключей
Генераторы — лучшие друзья первичных ключей Надо сказать несколько слов о реализации первичного ключа. Так как он предназначен для обеспечения уникальности, то никакие две записи в одной таблице не могут иметь одинаковых значений этого ключа. То есть, чтобы
Генераторы текстур
Генераторы текстур В состав Filters Unlimites входит несколько генераторов текстур. Подобные эффекты больше всего пригодятся разработчикам трехмерных игр и других 3D-проектов.При помощи фильтров категории Paper Backgrounds (Фон бумаги) можно создать текстуру поверхности любого типа
15.3. Генераторы специализированного кода
15.3. Генераторы специализированного кода Unix имеет давнюю традицию поддержки инструментов, которые специально предназначены для генерации кода для различных специальных целей. Давними «монументами» данной традиции, которые «уходят корнями» в Version 7 и ранние дни Unix, а также
15.3. Генераторы специализированного кода
15.3. Генераторы специализированного кода Unix имеет давнюю традицию поддержки инструментов, которые специально предназначены для генерации кода для различных специальных целей. Давними «монументами» данной традиции, которые «уходят корнями» в Version 7 и ранние дни Unix, а также
Генераторы перестановок (Permutation generators)
Генераторы перестановок (Permutation generators) template ‹class BidirectionalIterator›bool next_permutation(BidirectionalIterator first, BidirectionalIterator last);template ‹class BidirectionalIterator, class Compare›bool next_permutation(BidirectionalIterator first, BidirectionalIterator last, Compare comp);next_permutation берёт последовательность, определённую диапазоном [first, last), и
Аддитивные генераторы
Аддитивные генераторы Второй стандартный метод получения «более случайных» чисел от простого генератора называется аддитивным.В соответствии с этим методом, мы инициализируем массив чисел с плавающей запятой с помощью простого генератора, например, минимального
Тасующие генераторы
Тасующие генераторы И последний тип рассматриваемых нами генераторов, позволяющих получать «более случайные» числа, принадлежит к алгоритмам тасования. Здесь мы опишем генератор, реализованный на основе одного внутреннего генератора, хотя существуют и другие





